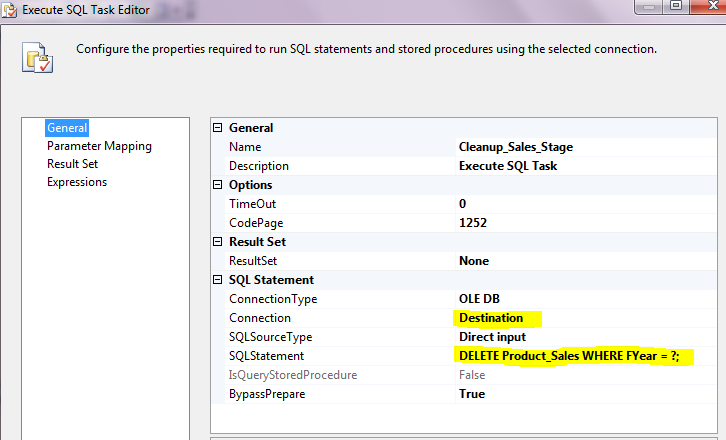
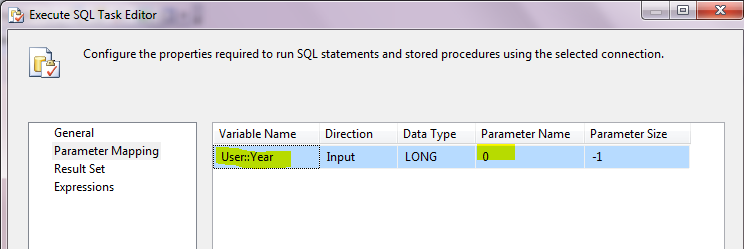
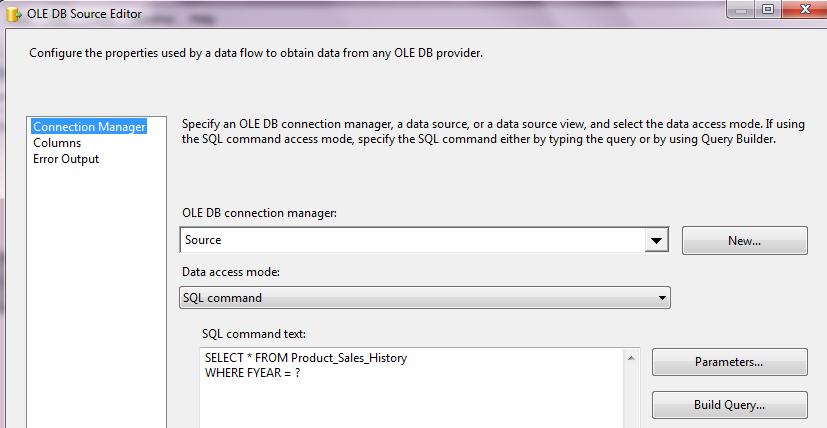
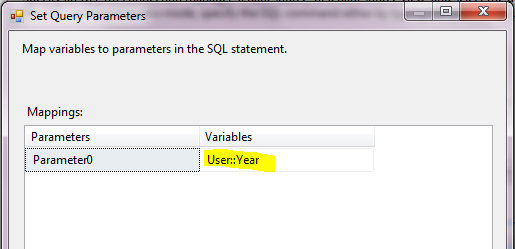
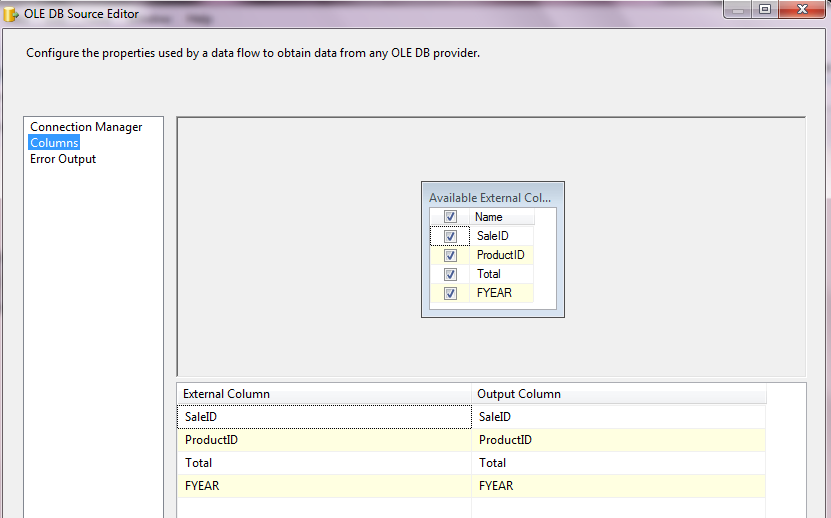
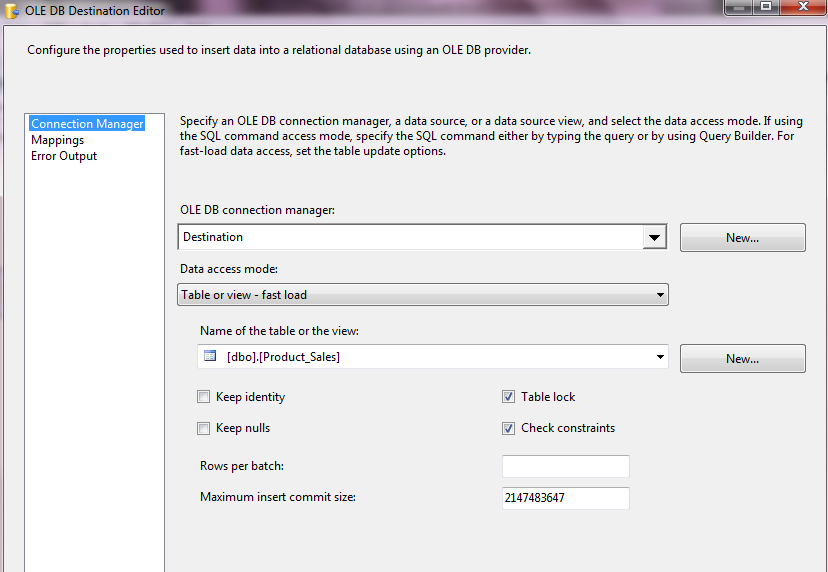
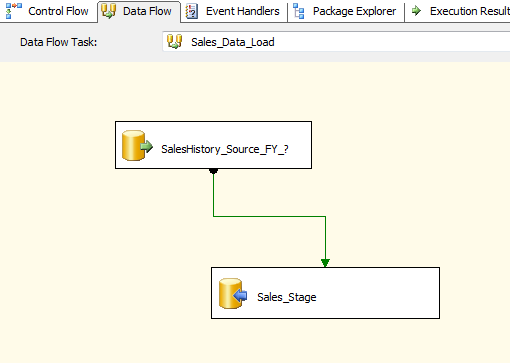
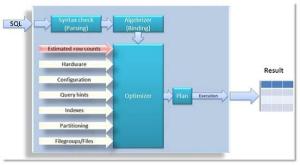
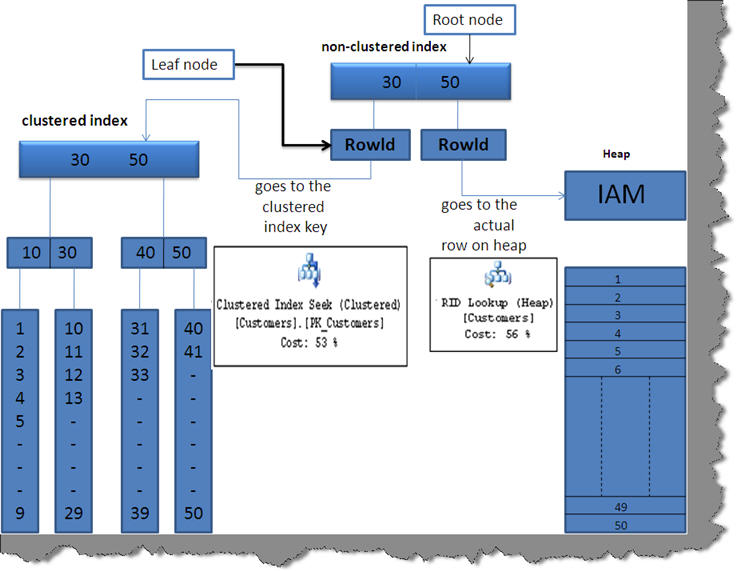
Hello All, I have been collecting interview questions from the people who given interviews at various organizations. Below are the list of questions. It includes, SQL DBA, MSBI, SQL Developer, SQL Server.
1
![]()
| Organization |
Microsoft IT |
| Position |
MSBI Developer |
| Location |
Hyderabad, India |
SSRS:
1. How to render a report to a user email?
2. How to join two datasets and use in a single report?
3. How to do paging in SSRS?
4. How to deal with multi valued parameters?
5. I want one page should be displayed in landscape and other pages in different formats in a report. Can you design a SSRS report for this requirement?
6. How to tune the performance of SSRS report?
7. How to design a Drilldown report?
8. What is the difference between Table and Matrix?
SSIS:
1. Design a SSIS package for the following requirement. Create a table, load data and move to the different schema using SSIS.
2. Are you following any framework for ssis?
3. How to execute parent and child ssis packages? Locate 1000 files location?
4. How to add users to a database using SSIS?
5. Which tasks should be used to import a million records txt files?
6. What are the configuration options for parent child packages?
7. What is the new configuration option added in SQL Server 2012?
8. What is the difference between “Execute SQL” and “Execute T-SQL” tasks?
T-SQL:
1. Why we can’t put Order by inside the view?
2
![]()
| Organization |
Berkadia |
| Position |
Sr. MSBI Developer |
| Location |
Hyderabad, India |
1. How to call a web service from SSIS?
2. What are the performance issues you have faced in SSIS?
3. Why SSIS? What is the use of ETL?
4. What is difference between SSIS and SSAS?
5. What is a dimensional databases?
6. Difference between Dim and Relational?
7. What is a cross apply and how to use this?
8. How to handle a result set from a webservice or Execute SQL task?
3
![]()
| Organization |
Capgemini |
| Position |
Sr. MSBI Consultant |
| Location |
Hyderabad, India |
!. What is a surrogate keys? How to call a unique column in dimension?
2. I have a table
Customer Book
C1 B1
C2 B1
C3 B1
I need output: All combination of all customers. Only distinct values
Example:
Customers
C1,C2
C1,C3
C2,C3
3. Can we use more than one CTE in a single select query?
4. We have three tables (Customer, Targets and Sale tables)
Customer – CID, CName
Targets – TID, CID, Target_Amt
Sale – SAID, CID, Sale_Amt
I need an output as below:
CID, CName, Total_Target_Value, Total_Sale_Value
;WITH CTE AS (
select t.cid,sum(t.target_amt) as targets
from targets t
group by t.cid)
select c.cid,
c.cname,
ct.targets AS ‘Total_Target_Value’,
sum(s.sale_amt) as ‘Total_Sale_Value’
from customer c
INNER JOIN SALE S on S.cid=c.cid
INNER JOIN cte ct on ct.cid=c.cid
group by c.cid,c.cname,ct.targets
5. What is drill across through report?
6. How to implement type 2 SCD using SSIS and queries?
4
![]()
| Organization |
Bank of America |
| Position |
Sr. MSBI Developer |
| Location |
Hyderabad, India |
1. I have opened a nested transaction inside an outer transaction, if i do rollback which transaction will be undone?
2. How do you know the total transaction count?
3. I have created a table variable can we use it in a nested stored procedure? If not what is the scope of a table variable?
4. If suppose we have a user defined data type. If we can modify the length of the data type does it effects in all places across the database?
5. Can we fire a trigger manually?
6. What are the magic tables? Do we have “Updated” magic table?
7. What is the difference between UnionAll and Merge?
8. What is Copy Column transformation?
9. I have a requirement that task2 has to be executed irrespective of Task1 result. How can you accomplish this?
10. Basic difference between stored procedure and user defined function?
11. See we have a simple query that’s calling a static function, like “Select * from employee where joiningdate < getstaticdate()”? Does it call function for every time or only for matched rows? How you tune this query?
12. Can we call Dataflow as a container?
13. While using SQL configurations, how you let your package direct to choose the package configuration file?
14. Do you use a single package or multiple packages for all environments?
15. Your dataflow is configured to use event handlers. I wanted one of the transformation inside the dataflow should skip the
16. What are the latest features in SSIS 2012?
17. How to use configurations in SSIS?
18. How to validate data in SSIS? Give some example.
5
![]()
| Organization |
HCL |
| Position |
Sr. MSBI Developer |
| Location |
Bangalore, India |
1. How to keep header in all pages – SSRS?
2. How to add custom code to change the colour of a node in report – SSRS
3. I have some .csv files, how to load them into SQL Server explain step by step.
4. How to send a report as an attachment to an email and HTML report should not be added.
5. What is the difference between OLEDB – Provider , ADO.NET and SQL Server destination?
6
![]()
| Organization |
Liquidhub |
| Position |
MSBI Consultant |
| Location |
Hyderabad, India |
1. What is a hash join in execution plan?
2. What is a sub report?
3. Difference between drill through and sub reports?
3.What is a shared dataset?
4. Can we use shared dataset with the subreport?
5. What is the deployment mechanism for SSRS deployment?
6. What are the common performance issues in SSRS?
7. Can you tell me top 5 new features in SSIS and SSRS Both in 2008 and 2012?
7
![]()
| Organization |
BARCLAYS |
| Position |
Sr.MSBI Developer |
| Location |
Singapore |
1. What kind of dashboards you have prepared using SSRS reports?
2. Have you ever tried logging in SSIS? What are the tables on which log information stored? Can we enable logging for only selected items from SSIS package? if yes how?
3. Design a package to load .xlsx files from a folder. File names must include either “Finance_” or “Local_” and load files only from the last week.
4. How to capture column name and row number when something failed in dataflow?
5. Design a SSIS package to load a list of excel files. Once a file is loaded that file should be moved / archived to new location.
6. Write a query to retrieve all employee hierarchy in an organization?
7. Design a SSRS report that can support dynamic columns.
8. Why should we use CTE?
9. How to use partition tables?
10. What is ETL, why specially SSIS?
11. What’s the max parallel value to SSIS?
12. See I have written a recursive CTE, it’s been running infinitely and failed with an error. The requirement is that the recursion required for 45000 times. How could you be able to handle the situation?
8
![]()
| Organization |
Franklin Templeton |
| Position |
Sr.Associate – MSBI |
| Location |
Hyderabad, India |
Q. SSIS 2008 uses all available RAM, and after package completes Memory is not released. Have you ever faced these issues if yes can you explain how you resolved it?
Q. Can you give some examples for de-generated dimension?
Q. We have a requirement like this. For every 10 days there is a data load happens in our database using a SSIS package. My requirement is once the ETL finished successfully then a SSRS report has to be emailed to the corresponding group of members. How can you do that?
Q. How to remove PDF from the export options in SSRS report?
Q. What are the different approaches to deploying SSIS packages in development, staging and production environments?
Q. Did you remember any error codes which are occurred while executing SSIS package?
Q. I have executed an SSIS package, usually it takes 3 hours but this time the package has taken 7 hours and the execution is still in progress. Can you describe what all the various approaches to troubleshoot this issue?
9
![]()
| Organization |
Cognizant |
| Position |
Sr.Associate – MSBI + T-SQL |
| Location |
Hyderabad, India |
1. Do you know about BI Symantec Model (BISM)?
2. Have you experienced filter index partitions
3.What is the difference between sub query and correlated query
4. What is the difference between pessimistic locking and optimistic locking?
5. What are the user roles available in SSRS?
6. Can you write a query to find nth highest salary of an employee?
7. Write a query to delete duplicate records from a table. Note: Write queries that suits the below situation. A table is having a unique key and having duplicates records, table is not having a unique and having duplicate records.
8. What is XACT_ABORT ON?
9. How to filter nested stored procedure code from profiler?
10. How to find the number of transactions in the current scope?
11. What happens when a rollback happens in inside a nested stored procedure?
12. Example for degenerated dimension?
13. What is a bitmap index?
14. How to avoid bookmark lookup in execution plan?
15. How to avoid sort operation in SSIS?
16. When index scan happens?
17. What are the data regions in SSRS?
10
![]()
| Organization |
Tech-Mahindra |
| Position |
Technology Lead – MSBI + T-SQL |
| Location |
Hyderabad, India |
1. What kind of join happens in lookup transformation?
2. Did you find any issues using Full cache mode?
3. Does temp tables and table variables both stored in tempdb?
4. Why cursors are so costly?
5. Have you ever used custom assembles in SSRS?
6. How to enhance SSRS functionality?
7. Can we move sql server logins and users using SSIS?
8. Which is the most critical ETL task you implemented using SSIS?
11
![]()
| Organization |
Datamatics |
| Position |
Consultant – MSBI + T-SQL |
| Location |
Bangalore, India |
1. Can we call a procedure from a function?
2. Can we write DML inside a function?
3. How to design a report to show the alternative rows in a different colour?
4. Write a code to customize the SSRS report. Where the code has to be written?
5. In a SSRS report where to write custom code?
6. How to troubleshoot SSRS report using ExecutionLog2?
7. Have you ever seen .rdl file? What are the different sections in .rdl file?
12
![]()
| Organization |
Hitachi Consulting |
| Position |
Sr.SQL Developer |
| Location |
Hyderabad, India |
1. What is the best value for MAXDOP value?
2. Which is better “Left Outer” Or “NOT EXIST”? Explain.
3. How to find the statistics are outdated?
4. How to find the query running on a given SPID?
5. What is XACT_ABORT ON?
6. Can we use two CTE’s in a single select query?
7. What are the different join operators in SQL Server?
8. Can we use a table variable inside a nested stored procedure if the table variable created in parent stored procedure?
9. What are the limitations on “SET ROWCOUNT”?
10. While creating a “Include” columns on which basis we should consider main column and include columns?
11. How to find the last statistics update date?
13
![]()
| Organization |
S&P Capital IQ |
| Position |
Sr. Database Engineer |
| Location |
Hyderabad, India |
1. An indexed view is referring only one base table. Both view and table are having index defined on them. Which index would be utilized when a query executed against the table.
2. I have an indexed view, now base table data has been modified, does the modified data reflected in view automatically?
3. Does “TRUNCATE” DDL or DML command?
4. I have written a recursive CTE, it’s been running infinitely and failed with an error. The requirement is that the recursion required for 45000 times. How could you be able to handle the situation?
14
![]()
| Organization |
innRoad |
| Position |
Sr. SQL Server Developer |
| Location |
Hyderabad, India |
1. What is index reorganization?
2. How sql engine knows which index has to be used while dealing with indexed views?
3. How to prevent bad parameter sniffing? What exactly it means?
4. What dll file that handle the transaction logs in logshipping?
5. How to find all dependent objects of a table?
6. How to find the latency in replication?
7. What are the tracer tokens in replication?
8. How to remove articles with generating a new snapshot?
9. I am not able to select some of the articles from publishing list, what might be the reason?
10. What is DAC? How it exactly works?
11. On which port DAC runs on?
12. Which agent will take care of database mirroring?
15
![]()
| Organization |
Tech Mahindra |
| Position |
SQL DBA |
| Location |
Hyderabad, India |
1. Why can’t we take a backup of a database which is in standby or in recovery mode?
2. How to move a database which is acting as a publisher in transactional replication?
3. What is CROSS APPLY?
4. How to find and remove duplicates from a table which is having 10 million rows?
5. Which is better a CTE or a subquery? Why?
6. Can you tell me replication monitoring tables?
7. How to apply service packs on Active Active cluster?
8. Best practices in applying security patches
9. What is a log reader agent?
10. What is PULL and PUSH subscriptions?
16
![]()
| Organization |
IBM |
| Position |
SQL DBA |
| Location |
Hyderabad, India |
1. How to rebuild a master database? Ho to restore a master database?
2. Any alternative to triggers?
3. What are the counters to monitor CPU usage?
4. Top 5 performance tuning tools
5. What events need to be added to capture execution plan in sql profiller?
6. How to add memory to sql server 2005?
7. Which locks are held at the time of snapshot in log shipping?
8. What is the new lock escalation in sql 2008?
9. How to check the log file location for service pack 4 in sql server 2005?
10. What is a filtered index?
17
![]()
| Organization |
Virtusa |
| Position |
SQL DBA |
| Location |
Hyderabad, India |
1. On which basis merge replication works on?
2. How to give a user to run a sql agent job?
3. Can we install SQL Server using a configure file?
4. What are the top performance counters to be monitor in Performance Monitor?
5. How do you know how much memory has been allocated to sql server using AWE?
18
![]()
| Organization |
Microsoft R&D |
| Position |
SQL Server Oops Lead |
| Location |
Hyderabad, India |
1. What happens when a transaction runs on SQL server? Let’s say simple update statement “Update Table set col1 = value where col2 = value”
Ans:
It issues an update lock and upgrades it to Exclusive Lock
The corresponding page would be captured from disk to memory
The modified page will be modified at Memory
The operation “Update *******” will be written to LDF.
Check point happens and the modified page will be written back to Disk and the operation at LDF marked as committed.
Lazy writer is responsible for cleaning the committed transactions from LDF.
2. What is fragmentation? How it happens?
3. See we have a full backup on Sunday 8 PM, Diff and every day : 8 PM and log bkp on every 15 min. DB Crashed on Saturday afternoon 2:55 PM. How to rebuild the database? If suppose the last Sunday full backup is corrupted then how can you restore the database in current in time?
4. I have an instance on which there are databases in both FULL and SIMPLE recovery models. If I restart the sql service, what is the difference between these databases in recovering or what happens while restarting the services?
5. I have a log file which is of 250 GB. Log is full. We don’t have a disk space on any other drive for creating .ndf, auto growth is ON, and essentially there are no options to allocate new space for the file. What’s your action plan?
6. Can we do replication with mirroring? If yes what are the limitations?
7. Can we perform a tail log backup if .mdf file is corrupted?
8. Task manager is not showing the correct memory usage by SQL Server. How to identify the exact memory usage from SQL Server?
9. What is the option”Lock Pages in Memory”?
10. How to apply service pack on Active / Passive cluster on 2008 and 2012?
11. Can we configure log shipping in replicated database?
12. How to configure replication on cross domain instances?
13. Let’s say we have a situation. We are restoring a database from a full backup. The restore operation ran for 2 hours and failed with an error 9002 (Insufficient logspace). And the database went to suspect mode. How do you troubleshoot this issue?
14. Consider a situation where publisher database log file has been increasing and there there is just few MB available on disk. As an experienced professional how do you react to this situation? Remember no disk space available and also we can’t create a new log file on other drive
15. Can we add an article to the existing publication without generating a snapshot with all articles?
19
![]()
| Organization |
Genpact |
| Position |
Lead SQL DBA |
| Location |
Hyderabad, India |
1. Difference between 32 bit and 64 bit
2. How B-Tree formed for Clustered and non clustered indexes?
3. How B-Tree forms for indexes with included column?
4. Does alzebrizer tree stores in memory for stored procedures, views and constraints?
5. What is WOW and WOW64?
6. How to design TempDB files? And what is the limit?
7. What are the different queues of CPU?
8. Write a query to show what’s happening on instance with description?
9. How VLF’s created for tempDB?
10. When the checkpoint can happen? What it exactly do?
11. When the lazywriter happens and what it’ll do?
12. What is total server memory and target server memory?
13. What is memory grant in SQL Server?
14. Why resourceDB introduced?
15. How to move master database?
16. How to rebuild master database and what are the considerations?
17. What is a boot page?
18. What is fragmentation?
19. What is edition limitation in sql server 2008 for database mirroring with asynchronous mode?
20. Do you know why SQL Browser is?
21. How to upgrade SSRS reports?
22. How do you know that log shipping break down?
23. What is the difference between push and pull subscription?
20
![]()
| Organization |
E&Y |
| Position |
Sr. SQL DBA |
| Location |
Kochi, India |
1. Can we truncate a table which is participating in transactional replication?
2. How to identify log filling issue and can we issue shrink with truncate on publisher database?
3. How to filter the nested stored procedure or a command from profiler?
4. Can we add articles to the existing publication without initialization of the snapshot?
5. How MAXDOP impacts SQL Server?
6. How distributed transactions works in SQL Server?
7. Full back up size is 300 GB, usually my diff backup size varies between 300 MB and 5 GB, one day unfortunately diff backup size was increased to 250 GB? What might be the reason any idea?
8. What is .TUF file? What is the significance of the same? Any implications if the file is deleted?
21
![]()
| Organization |
Infosys |
| Position |
SQL DBA |
| Location |
Mysore, India |
1. Are tables locked during generating the snapshot?
2. Does Truncate Works in replication? What are the limitations of Truncate command?
3. Causes for slow replication?
4. How to add articles to existing publication without generating a full snapshot?
5. Can we add only new articles to merger publication?
6. What is re-initialization in replication and how it works?
7. What is the difference between lazy writer and checkpoint?
8. How to move master database?
9. What are the different shrink options?
10. Can you explain the log file architecture?
22
![]()
| Organization |
Factset |
| Position |
MSBI Developer |
| Location |
Hyderabad, India |
1. What is the main difference between mirroring and always on?
2. What is Microsoft Best Practices Analyzer?
3. What is Microsoft Baseline Configuration Analyzer?
4. What are the different database patterns?
5. Any idea types of data warehouse?
6. What is SCD type – 2?
7. What is the difference between “Natural Key” and “Surrogate Key”?
8. What is a junk dimension? Give me an example
9. What is a Degenerate Dimension / Fact Dimension in SQL Server Analysis Services? In what scenarios do you use it?
23
![]()
| Organization |
Polaris |
| Position |
Technology Lead – DBA |
| Location |
Dubai, UAE |
1. What the issues you find in migrating databases
2. What is the schedule frequency of your transactional replication?
3. How do check the application compatibility with sql server?
4. How do you know whether statistics are latest or expired?
5. How to run distributed transactions in sql server? What are the config changes has to be made?
6. How to give linked server usage permissions to specified logins only?
7. What kind of information that SQL Server keeps in memory?
8. Customer asked to break the mirroring and failover to mirror database. What are the steps to be taken other than a manual failover?
9. Can you give some examples for One to One, One to Many and Many to Many relationships?
24
![]()
| Organization |
CA |
| Position |
Lead SQL DBA |
| Location |
Hyderabad, India |
1. How to find the tempdb contention?
2. What is the sparse file?
3. What is the redo file in log shipping?
4. What are the queues in sql server?
5. How to capture a trace from production without any impact on performance?
6. How to capture the long running queries?
7. What is the migration plan to move 300 databases to a new data centre? We can have an hour downtime.
8. In mirroring a connection failure happened between principal and mirror and principal server started filling log space (send queue), how do you troubleshoot?
9. What are the phases a database needs to be gone through while restoring?
10. What is the recovery interval?
11. You have any idea on Table Partitions?
25
![]()
| Organization |
Microsoft GTSC |
| Position |
SQL DBA |
| Location |
Bangalore, India |
1. We have a log shipping environment. New data file has been added at primary server, what happens and how do you resolve it?
2. See we have a view which is getting data from different tables. One day it’s starts executing infinitely. I have seen no blocking, no bulk operation happened. I have stopped all jobs and maintenance plans on the server. No one is connected to the database but still it’s been taking longer time. What might be the possible reasons?
3. You have got a request to execute a query which is an “Update” query. That update is updating 5 million rows, after an hour it’s still executing and you are getting lot of requests from report users that their things are getting slow down. What’s your action plan?
4. See I have an environment, Sunday night full backup, everyday night diff backup and every 45 min a transactional backup. Disaster happened at 2:30 PM on Saturday. You suddenly found that the last Sunday backup has been corrupted. What’s your recovery plan?
5. Full backup size is 300 GB, usually my diff backup size varies between 300 MB and 5 GB, one day unfortunately diff backup size was increased to 250 GB? What might be the reason any idea?
6. What is .TUF file? What is the significance of the same? Any implications if the file is deleted?
7. What are the ITIL basic standards? What are all the phases of ITIL? Explain about incident management, problem management, change management etc?
8. Can you explain sql server transaction log architecture?
9. What are the phases of sql server database restore process?
26
![]()
| Organization |
Pythian |
| Position |
Sr. SQL DBA |
| Location |
Hyderabad, India |
1. How many IP’s required configuring a 2 node cluster?
2. How many MSDTC required for a 2 node cluster?
3. What is the basic difference between 2005 and 2008 in clustering?
4. What’s the use of quorum in clustering?
5. Your customer complained that one of the reports is not working, what is your action plan? Note: You just know the database server not anything else about that report.
6. How could you give full access on a database to a user from “Operations-Team”. Remember the user should have all rights except write permission. But our company policy is not to give DB_OWNER rights to any user from “Operations-Team”
7. I wanted to know what are the maximum worker threads setting and active worker thread count on sql server. Can you tell me how to capture this info? What’s the default value for max thread count?
8. What are the all possibilities that cause the tempdb full issue?
9. What is version store?
10. What is the best configuration for Tempdb?
11. We have a procedure which is running fine till today afternoon. Suddenly it started taking long time to execute and there of it leads to a timeout error from application. What might be happening? How you troubleshoot?
12. Do you have any idea about sparse column?
13. Have you ever done any automation in your database environment?
14. What are the critical issues you faced in your career?
15. Did you ever handle any missed SLA’s?
16. How to change the port number for SQL Server?
17. Any idea about capacity planning?
27
![]()
| Organization |
DST Worldwide Systems |
| Position |
MSBI Lead |
| Location |
Hyderabad, India |
1. How to give estimations to your report requirements?
2. Difference between ISNULL and COAELSCE
3. What is the tough SSIS package you handled?
4. What is the difference between BCP and Bulk insert?
5. On which basis we can give the deadline for a given task?
6. I have a requirement: We need to load a bunch of files on every Thursday at 4:00 AM EST and once the load is completed successfully a pre designed SSRS report has to be triggered and it has to be mailed to the given recipients. Design a ETL package using SSIS
28
![]()
| Organization |
Yash Technologies |
| Position |
MSBI Lead |
| Location |
Hyderabad, India |
1. Write a query to capture all employee details with salary less than the average salary within each department.
2. I have a table employee in that I have a column empID which is of varchar type. The column may have combination of characters and integers. Now write a query to get all records in which empID are having integers. Exclude rows with EMPID is not having integer values in it.
3. We are doing a ETL operations using stored procedures. Write a procedure to cleansing data in staging table and insert the data into master tables. Remember in staging table all columns are of varchar type
4. What is database unit testing? How to perform unit test for a stored procedure and SSIS package?
5. Assume we need to design a SSIS package to load data from a .csv file to database. In .csv file there are 10 columns. For the first 500 rows data is available for all 10 columns and for the last 400 rows data is available for first 6 columns, not even comma available after 6th column. How do you handle this?
.csv file:
col1, col2, col3, col4, col5
‘dat’, ‘dat’, ‘dat’, ‘dat’, ‘dat’,
‘dat’, ‘dat’, ‘dat’, ‘dat’, ‘dat’,
‘dat’, ‘dat’, ‘dat’, ‘dat’, ‘dat’,
‘dat’, ‘dat’, ‘dat’
‘dat’, ‘dat’, ‘dat’
‘dat’, ‘dat’, ‘dat’
6. What are the different types of storage models in OLAP?
7. What is a mini dimension?
8. Design a SSRS report that can support dynamic columns.
9. How to remove PDF option from export options in SSRS report?
10. How to design a SSRS report that shows alternative rows in different colour?
29
![]()
| Organization |
L&T Infotech |
| Position |
Sr. MSBI Developer |
| Location |
Bangalore, India |
1. What is connection pooling in sql server?
2. Difference between partition by and patindex
3. What are the database design patterns?
4. What are the storage models in OLAP?
5. What is the difference between CROSS / OUTER APPLY AND JOINS in T-SQL?
6. When to use CROSS APPLY over Join?
7. Do you have any idea about table partitions?
8. How to attach configuration files to SSIS package?
9. What is stuff function? Difference between stuff and replace?
10. What is sparse column?
11. We have a query which is running fine in development but facing performance issues at production. You got the execution plan from production DBA. Now you need to compare with the development execution plan. What is your approach?
12. How to manually allocate memory to SSRS service?
13. How to view report server logs and call stacks in SSRS?
14. We know in SSRS by default datasets are executed in parallel. But in our environment datasource is under high load and can’t handle parallel requests. Now can you explain how to disable parallel processing or how to serialize dataset execution?
15. How to pass multi-valued parameter to stored procedure in dataset?
16. How to control the pagination in SSRS?
17. What are the major differences between SSRS 2008 and SSRS 2012?
18. You have any idea about IIF, SWITCH and LOOKUP functions in SSRS?
19. How to get “Total” values at the end of every group in a report?
20. A SSIS package failed how to know the exact row number at which the package failed to process?
The post Interview Questions appeared first on udayarumilli.com.